先月予告した通り、連載企画「個人名典拠ファイル入門」始まります。
「そもそも、個人名典拠ファイルってなに?」
そんな疑問にまずはお答えします。
個人名典拠ファイルとは、図書に〈著者〉または伝記や人物研究の主題として出現する個人名=〈被伝者〉として出現した個人名についてのデータベースです。
個人名典拠ファイルは、1つの名前につき1つ付与されるID(典拠ID)と、漢字形、カタカナ形(ヨミ)などから成り立っています。新しい人名が出るごとにファイルを作成しています。
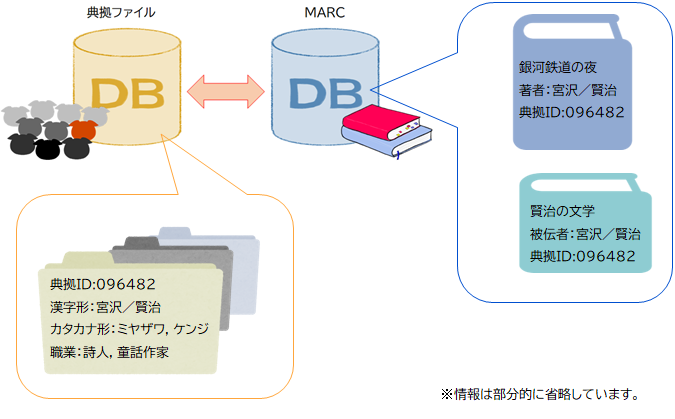
典拠ファイルはMARCとは異なるデータベースです。
これら著者・被伝者についてまとめられた個人名典拠ファイルは、書誌情報(MARC)と結び付いて提供されます。
...まだ、ちょっとイメージしづらいでしょうか?
もうすこし具体的に考えてみましょう。
たとえば、「宮沢賢治の本」を探していると言われたとき。何を思い浮かべますか?
宮沢賢治の書いた本、ということで「銀河鉄道の夜」や「注文の多い料理店」などがぱっと浮かぶでしょうか。〈著者〉が宮沢賢治の本ですね。
もしくは宮沢賢治のことについて書かれた本が浮かんだ方もいるかもしれません。
著者は文学研究者で、本の中で主題として宮沢賢治の作品を扱っています。
この場合、〈被伝者〉は宮沢賢治になります。
MARCには典拠ファイルのIDが入っていて、ふたつのデータベースはリンクしています。
こうして典拠ファイルとMARCが組み合わさることで、様々な便利な検索ができるようになるのです。
図にするとこのようなイメージです。
では、典拠ファイルにはどんな役割があるのか?
次回から詳しく説明していきます。
どうぞお楽しみに!